No artigo “Microsserviços: Projetando” apresentamos aspectos referentes ao desenvolvimento de aplicações baseadas em microsserviços. Neste post, vamos falar sobre formas de garantir sua confiabilidade.
Em uma arquitetura de microsserviços tipicamente existirão muitos deles em execução e, embora sejam autônomos, eles trabalham em cooperação e interdependência.
As falhas podem ocorrer em qualquer sistema complexo e não existem maneiras de evitá-las. Em microsserviços, principalmente devido à sua complexidade, esse aspecto não é diferente. Sendo assim, como podemos criar microsserviços confiáveis?
Para podermos falar em confiabilidade, é importante definir antes alguns termos para nortear nossa discussão:
- Disponibilidade: é um resultado de desempenho, calculado em função do tempo em que o componente esteve em funcionamento (uptime) e do tempo em que esteve parado (downtime). Assim, podemos dizer que é a habilidade de um componente de desempenhar a sua função quando requerida.
- Nível de Confiabilidade: é definida como a probabilidade de um componente (ou sistema) desempenhar sua função sem falhas durante um determinado período de tempo e sob determinadas condições. É, portanto, uma expectativa de desempenho definida a tempo de projeto. Quanto maior for o tempo em que o serviço funciona sem apresentar falhas, maior é o nível de confiabilidade deste serviço.
Embora o nível de confiabilidade seja um critério que também pode ajudar a medir a disponibilidade de um serviço, são métricas bem distintas. Por exemplo, podemos ter um serviço com alta disponibilidade, mas com baixos níveis de confiabilidade e vice-versa. Portanto, é importante olhar o serviço tanto do ponto de vista de disponibilidade como de nível de confiabilidade.
Sabendo que não é possível ser totalmente confiável (não existe 100% de confiabilidade), é importante admitir que falhas ocorrerão. Sendo assim, é necessário buscar soluções para maximizar a disponibilidade dos microsserviços e da aplicação, ou seja:
- Diminuir a incidência das falhas que podem ser evitadas;
- Limitar a propagação do impacto de uma falha no sistema;
- Buscar mecanismos de recuperação rápida quando uma falha ocorrer. De preferência essa recuperação deve ser feita de forma automática.
Criando Microsserviços Confiáveis
Dado que as falhas são inevitáveis e estão fora do nosso controle, a estratégia é projetar aplicações e microsserviços resilientes, isto é, que saibam se recuperar de situações de falhas.
Um ponto importante quando se projeta para resiliência é encontrar o equilíbrio entre o risco de uma falha realmente ocorrer e todo o trabalho que precisa ser realizado para se prevenir desse risco, uma vez que esse trabalho implica em custo e tempo para ser realizado.
O primeiro passo para encontrar essas possíveis soluções é identificar quais são as fontes de falhas possíveis e, para uma dada aplicação, quais dessas falhas podem ocorrer. Assim, seremos capazes de identificar os riscos associados à aplicação, definir melhores estratégias para mitigar os problemas resultantes dessas falhas, e também para realizar uma rápida recuperação quando ocorrer uma delas ocorrer.
Falhas
Algumas fontes de falhas que podem ocorrer em aplicações de microsserviços:
- Podem existir erros no próprio código do microsserviço;
- A rede e o ambiente dos microsserviços não são confiáveis;
- A implantação pode não ser estável;
- Problemas na infraestrutura (como recursos saturados ou indisponíveis);
- Indisponibilidade de algum microsserviço;
- Erros humanos;
- Problemas de comunicação.
Essas fontes de falhas podem ser classificadas em quatro categorias, dependendo do ponto de interação entre o microsserviço e qualquer outro componente do sistema: falha interna, falha de dependência, falha de hardware e falha de comunicação. Ademais, precisamos considerar a questão da propagação de uma falha, já que os microsserviços interagem entre si.
Falhas de hardware
As falhas decorrentes do hardware, por exemplo, falha do servidor, da rede ou de contêineres, são as mais críticas porque podem afetar muitos microsserviços ao mesmo tempo. Neste caso, aplicar mecanismos de redundância é uma forma de minimizar o impacto dessa falha, mas irá certamente acarretar custos adicionais. Dimensionar corretamente o nível de redundância necessária é fundamental.
Falhas de comunicação entre os microsserviços
As falhas provenientes da comunicação entre os microsserviços estão relacionadas, por exemplo, com a conectividade da rede, com erros de DNS e com sistemas de mensagens. Normalmente as questões referentes à rede estão relacionadas a alterações de configurações ou novas liberações de serviços. Nesses casos, a realização de testes e mecanismos de rollback podem ajudar muito a minimizar o impacto desse tipo de falha.
Falha de dependências (internas ou externas) dos microsserviços
As falhas referentes às dependências (internas ou externas) dos microsserviços também são comuns e podem ser resolvidas com técnicas de resiliência que trataremos mais adiante nesse texto, bem como através de boas práticas de engenharia de software no desenvolvimento e na implantação dos microsserviços.
Existem alguns recursos importantes que podem ser usados para aumentar a resiliência de microsserviços e lidar com as eventuais falhas, seja qual for sua origem. Os recursos em questão podem ser patterns (por exemplo, Timeout) usados na construção dos microsserviços (ou em componentes de apoio utilizados por eles, como o sidecar da camada de Service Mesh) ou técnicas de resiliência (por exemplo, balanceamento de carga).
Comunicação Resiliente
Para conseguir uma comunicação com maior grau de resiliência, podemos utilizar alguns padrões como Retry, Fallback, Timeout e Circuit Breaker. Vejamos a descrição de cada um desses patterns:
Retry Pattern
Esse pattern pode ser usado quando alguma requisição (chamada a outro microsserviço ou componente externo) falha. Inicialmente, o microsserviço que fez a chamada não sabe se essa falha ocorreu de forma transiente ou definitiva. Então, uma nova tentativa (retry) de requisição é realizada. Se a falha persistir, pode-se usar um tempo variável entre sucessivas tentativas, tomando o cuidado de estabelecer um número máximo de tentativas.
Caso o serviço alcance o limite máximo de tentativas, pode-se simplesmente aceitar a falha ou tentar uma alternativa para atender essa requisição.
Muitas vezes o Retry Pattern é usado em conjunto com o Circuit Breaker Pattern, para evitar novas chamadas a serviços que estão fora do ar ou estão sobrecarregados.
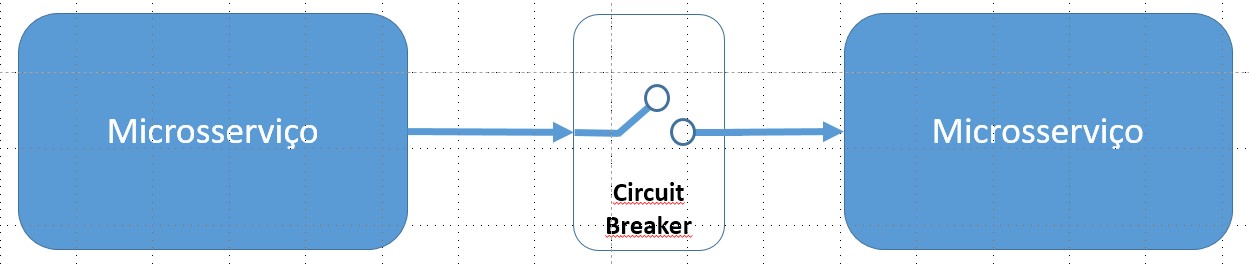
Circuit Breaker Pattern
De forma similar ao anterior, esse pattern pode ser usado para cessar requisições que estejam sendo feitas para um microsserviço que não está funcionando (em falha), evitando assim a propagação dessa falha.
A ideia aqui é controlar o número de tentativas de chamadas malsucedidas a um microsserviço e, caso ele ultrapasse um limite pré-estabelecido, o circuito é colocado em estado aberto e novas requisições falham imediatamente. Em um determinado momento, o circuito envia uma requisição para testar se o serviço voltou a ficar disponível, ficando nesse momento em estado semi-aberto. Caso a requisição seja bem-sucedida, o circuito volta a ficar fechado e tudo se normaliza. Caso contrário, o circuito volta a ficar aberto.
Fallback Pattern
Fallback significa contingência, e é um termo comumente usado na engenharia para designar o planejamento de procedimentos necessários para restaurar um sistema quando ele falha, retornando-o à condição operacional.
O Fallback Pattern nada mais é do que utilização de alternativas quando a opção preferida não está disponível. Este pattern é usado quando uma chamada a um serviço falha, e são realizadas ações alternativas como, por exemplo, chamar um outro serviço que ofereça informações semelhantes (redundância funcional), retornar um valor armazenado em cache (mesmo que desatualizado) ou devolver um valor padrão.
Timeout Pattern
O Timeout é um temporizador que é programado antes de se chamar um serviço externo e estabelece o tempo máximo de espera pela resposta desse serviço. Se esse limite de tempo for atingido, a espera deve ser interrompida, retornando um erro. Esse mecanismo evita que um microsserviço fique indefinidamente bloqueado à espera de uma resposta que poderá ser recebida (por falha no serviço chamado ou no meio de comunicação).
Entretanto, o uso de Timeout pode ser um problema quando um determinado serviço for constituído por uma sequência de microsserviços em cadeia. Suponhamos que cada microsserviço, para chamar o microsserviço seguinte da cadeia, estabelece seu temporizador de maneira independente (e provavelmente com valor idêntico aos que o antecedem na cadeia). Mesmo que o último serviço responda em tempo à chamada, pode ser que os temporizadores dos primeiros serviços da cadeia já tenham expirado, o que os fará desprezar as mensagens de retorno, gerando um tráfego desnecessário de mensagens.
Nesse caso, pode-se implementar os chamados timeouts distribuídos ou deadlines. O deadline estabelece um timeout para a requisição completa (cadeia total de chamadas referente à requisição), a partir do momento em que a requisição inicial é realizada. À medida que a requisição é passada de microsserviço para microsserviço, cada um deles verifica o deadline, desconta seu timeout local e atualiza o deadline. Para que esse procedimento funcione é necessário que os microsserviços envolvidos respeitem uma convenção comum para deadlines.
Maximizando a Confiabilidade do Microsserviço
Além dos patterns de resiliência que acabamos de descrever, é possível maximizar a confiabilidade dos microsserviços, através de algumas técnicas de resiliência como: load balancing, rate limit e load testing. Todas essas técnicas utilizam informações baseadas no health checking pattern, que é o padrão que testa a integridade de um (micro) serviço.
Health Checking Pattern
Cada microsserviço que é projetado e implantado deve implementar um conjunto de técnicas de checagem de integridade e, quando uma instância desse serviço se torna unhealthy (falha alguma checagem de integridade), ela não deve mais receber tráfego proveniente de outros microsserviços. O health checking pattern propoõe várias verificações como:
- qual é o status das conexões com os serviços de infraestrutura usados pela instância desse microsserviço;
- qual é o status do host onde o microsserviço está executando (por exemplo, qual o espaço em disco);
- outras checagens referentes a lógica da aplicação.
Embora esse pattern permita que a integridade de uma instância do microsserviço seja testada periodicamente, ele pode não ser suficiente, especificamente se o microsserviço falhar entre as checagens, o que poderia resultar no roteamento de requisições para uma instância do microsserviço que está com falha.
Esse pattern pode ser utilizado por outros serviços como monitoramento, registro de serviços, balanceador de carga ou qualquer outro que precise saber qual o status da integridade de uma instância do microsserviço antes de prosseguir com suas atividades.
Load balancing
No ambiente de produção, é comum a implantação de múltiplas instâncias de um mesmo microsserviço para garantir a redundância e a escalabilidade horizontal. Nesse contexto, o balanceador de carga (load balancer) pode ser usado para maximizar a confiabilidade dos microsserviços, distribuindo as múltiplas requisições para as diferentes instâncias do microsserviço.
Para poder distribuir adequadamente cada requisição entre as instâncias saudáveis do microsserviço, o balanceador precisa saber quais instâncias estão íntegras e, para isso, utiliza o mecanismo de health checking. Em comunicações síncronas, essa checagem periódica é realizada diretamente em cada instância do microsserviço. Em comunicações assíncronas, essa checagem é realizada verificando a conexão entre a fila de mensagens e as instâncias do microsserviço.
Alguns aspectos dessa checagem de integridade do microsserviço devem ser consideradas:
- A condição de liveness, que indica se o microsserviço foi inicializado e está executando corretamente.
- A condição de readiness, que indica se o microsserviço está pronto para receber requisições e, nesse caso, inclui também a disponibilidade dos componentes dos quais ele depende.
- O balanceador de carga deve manter indicadores sobre o tempo de resposta e taxa de erros de cada instância do microsserviço. Isso é necessário para poder identificar se uma determinada instância está em uma condição de degradação, com taxas de latência e erro cada vez maiores.
Com o resultado da checagem de integridade, o balanceador de carga pode tomar a decisão correta ao distribuir requisições. Esta distribuição é feita apenas para as instâncias que estão ativas, prontas e com melhor desempenho. O resultado é um incremento na confiabilidade e o desempenho do sistema.
Outros mecanismos
Com o objetivo de maximizar a confiabilidade dos microsserviços, outras técnicas podem ser utilizadas:
- Rate limits: para evitar o excesso de requisições a uma determinada instância de um microsserviço, aumentando o risco de sobrecarregá-la, pode ser estabelecido um limite máximo para o número de requisições que cada instância pode receber em um determinado período de tempo ou janela de execução. As requisições que ultrapassarem esses limites serão descartadas ou seguirão uma ordem de prioridade para serem atendidas em algum momento futuro. A estatística referente a pedidos descartados pode ser usada posteriormente para redimensionamento dos recursos disponíveis para atendimento da demanda;
- Testes de Resiliência: fundamental para garantir se o projeto de cada microsserviço está adequado para situações de falha. É importante realizar testes que simulem a execução do microsserviço em ambiente de produção sob situações normais e, principalmente, em situações que ultrapassem os limites normais e aceitáveis de tráfego e de requisições. Desta forma, será possível identificar gargalos ou erros de projeto ou de dimensionamento de recursos. Adicionalmente ao teste individual de cada microsserviço, é importante testar o ambiente como um todo para encontrar possíveis problemas provenientes da interação entre os microsserviços. Além disso, existem problemas que podem surgir quando falhas acontecem fora dos microsserviços (problemas na infraestrutura, rede, máquinas virtuais, etc). Para tentar evidenciar esses casos, podem usada a técnica de chaos testing, forçando todos os tipos de situações indesejadas possíveis no ambiente real de execução. Visite o site “Principles of Chaos Engineering” para conhecer mais sobre esses testes.
Considerações
Nesse texto apresentamos as questões referentes a disponibilidade e confiabilidade dos microsserviços. Embora não seja possível eliminar as falhas, é possível utilizar técnicas de resiliência para lidar da melhor maneira possível com essas ocorrências. Assim, se garante a máxima disponibilidade e confiabilidade dos microsserviços. O aspecto de comunicação é crucial nesse contexto.
Por fim, vale evidenciar que existem vários frameworks implementam muitas das técnicas e patterns apresentados aqui, bem como sidecars usados por Service Meshs, eliminando a necessidade de se construir tais elementos dentro de cada microsserviço. Para uma explanação sobre Service Meshs e sidecars, veja “Service Mesh – O que é e Por que usar?”.






